深入浅出 Elasticsearch 数据存储与查询的基本原理
Elasticsearch (ES) 作为一个开源的分布式搜索和分析引擎,其核心价值在于提供高效、可扩展的数据处理与存储服务。理解其基本原理,是构建健壮搜索、日志分析或实时数据监控应用的关键。本文将深入浅出地解析 ES 在数据存储与查询方面的核心机制。
一、 数据存储:索引、分片与副本
ES 的数据存储并非基于传统关系型数据库的表结构,而是围绕以下几个核心概念构建:
- 索引:索引是 ES 中最高层的数据逻辑容器,类似于关系型数据库中的“数据库”。它是一类具有相似特征文档的集合。
- 文档:文档是 ES 中可被索引的基本信息单元,以 JSON 格式表示,类似于数据库中的一行记录。每个文档属于一个索引,并具有一个唯一的 ID。
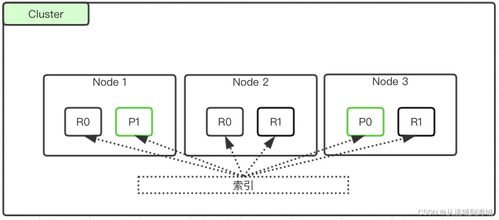
- 分片:为了实现水平扩展和海量数据存储,ES 将每个索引切分为多个分片。每个分片本身就是一个功能完备、独立的“索引”,可以分布在集群中的任意节点上。这允许数据并行处理和存储,突破了单机硬件限制。索引创建时可以指定主分片数量,后续不可更改。
- 副本:为了提高系统的可用性和读取性能,ES 允许为每个主分片创建一个或多个副本分片。副本是主分片的完整拷贝,提供数据冗余(防止硬件故障导致数据丢失)并分担查询请求的负载。
存储过程可以概括为:当一个文档被索引时,ES 首先根据文档 ID 路由到其所属索引的某个特定主分片。在该分片上,文档会经过分析(分词、标准化等)处理,然后构建倒排索引——这是 ES 实现快速全文搜索的基石。倒排索引记录了每个词项出现在哪些文档中,以及出现的位置和频率,而非像传统数据库那样逐行扫描。
二、 数据处理:分析与映射
在数据存入倒排索引前,ES 会对其进行一系列处理,这主要由两个环节控制:
- 分析过程:文本字段会经过分析器处理。分析器通常由字符过滤器、分词器和词元过滤器组成。例如,对于句子“Elasticsearch is powerful”,分析器可能会将其转换为小写,分词为 ["elasticsearch", "is", "powerful"],并可能移除停用词“is”,最终得到词项 ["elasticsearch", "powerful"] 存入倒排索引。这个过程使得后续可以基于词项进行高效的匹配。
- 映射:映射定义了索引中字段的数据类型(如
text,keyword,date,integer等)及其属性(如使用何种分析器)。正确的映射至关重要,它决定了数据如何被索引和存储。例如,text类型字段默认会被分析,适合全文搜索;而keyword类型字段则保持原样,适合精确匹配、排序和聚合。
三、 数据查询:搜索与检索原理
ES 的查询能力强大而灵活,其核心流程如下:
- 查询阶段:
- 当客户端发起一个搜索请求时,该请求会被发送到集群中的某个协调节点。
- 协调节点将请求转发到目标索引的所有相关分片(主分片或副本分片)。
- 每个分片在本地独立执行查询(在自身的倒排索引中查找匹配的文档),并计算出一个相关性得分(如 TF-IDF 或 BM25 算法),然后返回一个轻量级的文档ID和得分列表给协调节点。
- 取回阶段:
- 协调节点汇集所有分片返回的结果,进行全局排序、筛选,确定最终需要取回的文档列表。
- 协调节点再向持有这些文档数据的分片发送请求,获取文档的完整内容(
_source字段)。
- 协调节点将完整结果组装并返回给客户端。
四、 作为数据处理与存储服务的价值
综合以上原理,ES 作为一项服务,其优势体现在:
- 近实时性:文档索引后通常在1秒内即可被搜索到。
- 高可用与可扩展性:通过分片和副本机制,轻松实现水平扩展和容错。
- 强大的全文搜索:基于倒排索引和丰富的分析器,支持复杂的全文查询、模糊匹配、同义词等。
- 丰富的查询DSL:提供结构化查询、过滤、高亮、聚合分析等多种功能,满足复杂的数据分析需求。
- 面向文档的灵活性:JSON 文档格式无需预定义严格模式,支持动态添加字段。
###
Elasticsearch 通过将数据分布式存储于倒排索引支持的分片中,并结合一套高效的分析、映射和两阶段查询流程,实现了对海量数据的近实时、高性能检索与分析。掌握这些存储与查询的基本原理,有助于我们更好地设计索引、优化查询,从而充分发挥这一强大数据处理与存储服务的潜力。
如若转载,请注明出处:http://www.starunicom.com/product/25.html
更新时间:2026-04-15 09:31:51