工业物联网实时分析的秒级革命 拆解DolphinDB如何攻克海量数据下的预警与决策难题
随着工业物联网(IIoT)的迅猛发展,数以亿计的传感器和设备正以前所未有的速度生成着海量、高并发的时序数据。传统的批处理与准实时分析系统在应对这类数据洪流时,往往在延迟、吞吐量和成本上捉襟见肘,难以支撑起毫秒级预警、秒级决策的关键需求。在这一背景下,一场以“秒级”甚至“毫秒级”响应为核心的实时分析革命正在上演。作为这场革命的核心引擎之一,DolphinDB 凭借其深度融合时序数据库与流计算引擎的独特架构,为工业物联网的海量数据处理、实时预警与智能决策提供了全新的解决方案。
一、直面工业物联网的三大核心挑战
在深入解析 DolphinDB 的解决方案之前,首先需要理解工业物联网场景下数据处理的三大核心挑战:
- 数据规模与速度的爆炸性增长:单条产线或设备即可产生每秒数万甚至数十万点的数据,系统需具备极高的写入吞吐量(TPS)。
- 极致的实时性要求:从设备异常检测、工艺参数越界到生产安全预警,都要求在数据产生后的数百毫秒至数秒内完成计算与响应。
- 复杂分析与高并发查询的压力:在实时监控的还需支持对历史数据的高并发、多维度关联分析(如故障根因分析、能效优化),为决策提供依据。
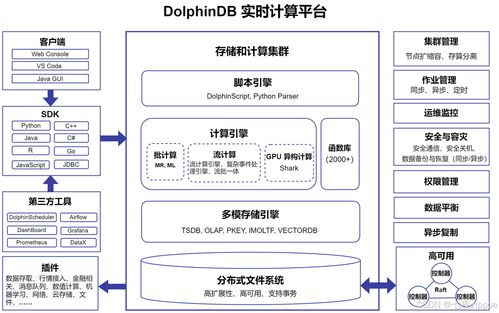
二、DolphinDB的架构革新:时序数据与流计算的深度融合
DolphinDB 之所以能够攻克上述难题,其根本在于打破了传统架构中“存储”与“计算”分离、批流分离的藩篱,实现了“时序数据库”与“流计算引擎”的原生一体化设计。
- 高性能时序数据存储引擎:
- 列式存储与高效压缩:针对时序数据高度有序、同列数据相似性高的特点,采用列式存储并结合多种高效压缩算法,大幅降低存储成本,同时提升数据扫描速度。
- 分区与索引机制:支持按时间、设备、标签等多维度的灵活分区策略,结合自适应索引,确保在海量数据中能够快速定位目标数据块,为毫秒级查询奠定基础。
- 内置的流计算与实时分析引擎:
- 发布-订阅式流数据表:数据在写入存储的可自动、低延迟地发布到流数据表中,供下游的流计算任务实时消费。
- 时间窗口聚合与状态计算:原生支持滚动窗口、滑动窗口、会话窗口等多种窗口计算,并能方便地进行复杂的状态维护(如设备连续异常次数统计),轻松实现如“5秒内温度连续3次超过阈值”的复杂预警规则。
- 流批一体SQL:用户可以使用统一的类SQL语言(DolphinDB Script)同时编写流处理任务和批处理分析任务,极大地简化了开发运维复杂度,实现了从实时预警到历史回溯分析的无缝衔接。
三、实战拆解:海量数据下的预警与决策实现路径
以一个智能工厂的预测性维护场景为例,拆解 DolphinDB 的工作流程:
- 数据高速注入:遍布工厂的振动、温度、压力传感器数据,通过 MQTT、Kafka 等协议,以每秒百万点的速度持续写入 DolphinDB 的分布式时序数据库集群。系统凭借其分布式架构和高效的写入接口,轻松应对这一洪峰。
- 实时预警规则引擎:
- 秒级规则计算:工程师通过简单的脚本定义流计算任务。例如,创建一个实时计算任务,对每台机床的振动频谱数据进行实时FFT变换,并监控特定频段的能量是否在最近10秒的滑动窗口内超过了历史基线值的2倍标准差。
- 即时触发与告警:一旦规则被触发,DolphinDB 的流计算引擎会毫秒级地输出告警事件,并通过内置接口或外部系统(如消息推送、API调用)实时通知运维人员,甚至联动控制系统进行预停机。
- 决策支持与历史洞察:
- 高并发交互式分析:当管理人员需要分析某类故障的共性特征时,可通过BI工具或API直接向 DolphinDB 发起复杂的关联查询(如“关联过去三个月所有发生过轴承故障的设备,对比其温度曲线与振动趋势”)。得益于其列存引擎和分布式计算能力,即使面对TB级历史数据,此类查询也能在秒级内返回结果。
- 模型训练与反馈闭环:DolphinDB 内置了丰富的统计分析与机器学习函数库。可以利用历史数据在库内直接训练故障预测模型,并将模型发布为一个流计算函数,实时对注入的新数据流进行在线评分,从而实现预警规则的自我优化与决策智能化。
四、革命性成效:从“事后追溯”到“事前预防”与“事中指挥”
通过上述技术路径,DolphinDB 助力工业企业实现了数据处理范式的根本转变:
- 预警延迟从“分钟级”降至“秒级”:将潜在故障的发现时间大幅提前,为干预措施争取宝贵窗口,避免非计划停机带来的巨大损失。
- 决策依据从“经验驱动”到“数据驱动”:实时数据与历史数据的无缝融合分析,使得工艺优化、排产调度、能效管理等决策更加精准、科学。
- 系统架构从“复杂拼装”到“统一平台”:一个 DolphinDB 集群即可替代原先由实时数据库、流处理框架(如Flink)、分析型数据库和缓存系统组成的复杂技术栈,极大降低了系统的开发、运维与总拥有成本(TCO)。
工业物联网的“秒级分析革命”本质是对数据价值释放速度的极致追求。DolphinDB 通过其创新的融合架构,不仅提供了处理海量时序数据的强大“数据处理和存储服务”,更构建了一个集实时感知、智能预警与深度分析于一体的决策中枢,成为工业企业数字化转型中应对数据挑战、挖掘数据实时价值的核心基础设施。
如若转载,请注明出处:http://www.starunicom.com/product/16.html
更新时间:2026-03-30 15:35:23