Zookeeper 核心概念、工作原理与典型应用场景剖析
Zookeeper是一个开源的分布式协调服务,由Apache软件基金会开发和维护。它为分布式应用提供了高效、可靠的配置维护、命名服务、分布式同步和组服务等核心功能。理解其概念、原理与应用场景,对于设计和构建稳健的分布式系统至关重要。
一、 核心概念
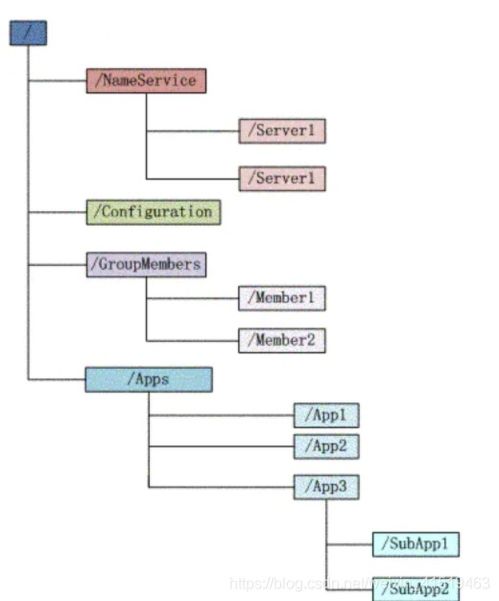
- 数据模型:Zookeeper的数据模型类似于一个标准文件系统,它采用一种称为 Znode 的层次化命名空间(树形结构)。与文件系统不同的是,Znode既可以存储少量数据(通常以字节数组形式,用于存储配置、状态等元数据),也可以作为路径节点。Znode分为持久节点和临时节点。
- 会话:客户端连接到Zookeeper服务器时会建立一个会话(Session)。会话有一个超时时间,在此期间,客户端可以通过心跳保持会话有效。如果会话超时,该会话创建的临时节点将被自动删除。
- Watcher机制:这是Zookeeper实现分布式协调的核心。客户端可以在Znode上设置一个监视点(Watcher)。当该Znode发生变化(如数据更新、子节点增减、节点删除)时,Zookeeper服务端会向客户端发送一个一次性通知,触发客户端预定义的回调逻辑。
- 集群角色:Zookeeper集群通常以奇数台服务器组成,包含以下角色:
- Leader:负责处理所有写请求,并通过ZAB协议进行事务提案和提交。
- Follower:处理客户端的读请求,并将写请求转发给Leader。参与Leader选举和事务提案的投票。
- Observer:与Follower类似,处理读请求并转发写请求,但不参与投票,用于扩展集群的读吞吐量。
- 一致性保证:Zookeeper提供顺序一致性,即来自客户端的更新请求将按发送顺序被应用。它提供的是最终一致性视图,但通过同步调用可以保证读取到最新数据。
二、 工作原理
Zookeeper的核心是其一致性协议——ZAB协议。ZAB是为Zookeeper专门设计的支持崩溃恢复和消息广播的原子广播协议。
- 消息广播(数据同步):所有写请求都由Leader处理。Leader会为每个写请求生成一个全局单调递增的事务ID,并将其作为提案广播给所有Follower。当超过半数的Follower返回ACK后,Leader会提交该事务,并向所有Follower发送提交消息,最终完成数据更新。这个过程保证了集群内各节点数据的最终一致性。
- 崩溃恢复(Leader选举):当Leader服务器宕机或与集群失去联系时,ZAB协议会进入崩溃恢复模式。剩余服务器会进行新一轮的Leader选举。选举标准是寻找具有最高事务ID的服务器。选举出新Leader后,新Leader会与所有Follower进行数据同步,确保所有服务器状态一致,然后重新进入消息广播模式。
三、 数据处理与存储服务
Zookeeper本身不是一个通用的海量数据存储或处理服务(如HDFS或Kafka)。它的定位是协调服务,其数据处理和存储具有以下特点:
- 存储内容:主要存储元数据、配置信息、状态信息和协调指令,数据量很小(每个节点数据上限通常为1MB)。
- 数据持久化:Zookeeper将数据存储在内存中以保证高性能,同时会将事务日志和快照持久化到磁盘,用于故障恢复。
- 数据处理模式:以读多写少的访问模式为主。写操作通过Leader达成共识,强一致性但吞吐量有限;读操作可以由任意Follower或Observer处理,响应快且吞吐量高。
- 数据变化通知:通过Watcher机制,客户端可以订阅关心的Znode,当数据变化时能及时感知,这是实现分布式锁、配置中心等场景的关键。
四、 主要应用场景
基于上述特性,Zookeeper在分布式系统中有着广泛的应用:
- 配置管理:将系统的通用配置(如数据库连接串、特性开关)存储在Zookeeper的Znode中。所有客户端监听该节点,当配置变更时,Zookeeper会通知所有客户端,实现配置的集中管理和动态更新。
- 命名服务:通过树形结构,可以像DNS一样,用一个路径名称来标识集群中的服务或资源,方便服务发现。
- 分布式锁:利用Zookeeper创建临时顺序节点的特性,可以实现公平的分布式排他锁和读写锁。这是其最经典的应用之一,常用于控制分布式系统对共享资源的互斥访问。
- 集群管理与选主:通过创建临时节点可以监控集群成员存活状态(机器上线/下线)。利用Znode的序列特性,可以轻松实现分布式Leader选举(例如,Kafka、Hadoop YARN等组件的控制器选举)。
- 分布式队列:利用顺序节点可以实现简单的FIFO队列或屏障同步。
- 作为分布式系统的基石:许多著名的分布式系统都依赖Zookeeper进行协调,例如:
- Apache Kafka:用于存储Broker、Topic元数据,并进行控制器选举。
- Apache HBase:用于管理RegionServer状态,并选举Master。
- Apache Hadoop YARN:用于资源管理器的选主。
- Dubbo:早期的版本使用Zookeeper作为服务注册中心。
###
Zookeeper以其简单的数据模型、可靠的通知机制和强大的一致性保证,成为了分布式系统领域不可或缺的“瑞士军刀”。它解决了分布式系统中常见的协调难题,如状态同步、配置管理和领导选举。开发者也需要意识到它并非万能,其设计目标决定了它不适合存储大量数据或处理高频写入场景。在系统架构中,正确地将Zookeeper用于其擅长的“协调”角色,方能最大化其价值。
如若转载,请注明出处:http://www.starunicom.com/product/19.html
更新时间:2026-04-07 19:05:49