OLAP技术选型 聚焦数据处理与存储服务的核心考量
在线分析处理(OLAP)系统的技术选型是构建高效数据仓库和商业智能平台的关键决策。其核心选型对象并非单一技术,而是围绕数据处理与数据存储两大服务体系展开,旨在满足海量数据下的快速、复杂查询与分析需求。
一、 数据处理服务选型
数据处理服务负责将原始数据转化为可供分析查询的形态,主要涉及数据计算引擎与查询引擎的选型。
- 计算模式与引擎:
- 预计算模式(MOLAP): 以Apache Kylin、Druid为代表。其核心是在数据写入时,根据预定义的维度和指标进行预先聚合计算,将结果存储在高度优化的多维立方体(Cube)中。选型考量点在于对查询速度的极致要求(可达到亚秒级响应)、查询模式相对固定且可预测的场景。缺点是灵活性较低,对即席查询支持弱,且可能存在数据膨胀。
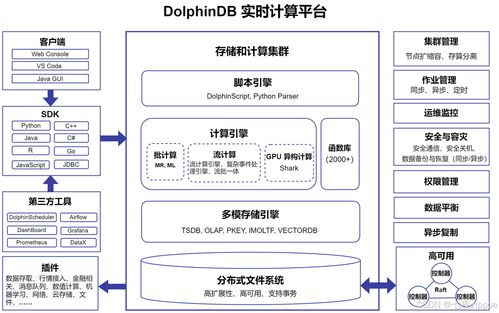
- 即时计算模式(ROLAP): 以Presto、ClickHouse、StarRocks、Apache Doris为代表。其直接在原始或轻度聚合的数据上进行SQL查询和计算。选型考量点在于需要支持高度灵活的即席查询、复杂的多表关联分析,且数据模型可能频繁变更。对底层存储的I/O性能和引擎的向量化计算能力要求极高。
- 混合模式(HOLAP): 结合两者优势,是当前许多现代OLAP系统的设计方向,允许在预聚合和明细数据之间智能选择。
- 查询引擎特性:
- 架构: 是MPP(大规模并行处理,如ClickHouse、Greenplum)还是基于云原生的存储计算分离架构(如Snowflake、StarRocks的更新版本)。前者追求极致性能,后者强调弹性与成本。
- 并发能力: 高并发查询场景(如面向数百上千业务人员的BI平台)需重点评估引擎的并发处理与资源隔离能力(如Impala、Presto)。
- SQL兼容性: 对标准SQL及特定方言(如Hive SQL)的支持程度,直接影响开发迁移成本和生态集成难度。
二、 数据存储服务选型
数据存储服务是OLAP系统的基石,决定了数据的组织方式、存取效率与成本。
- 存储格式与模型:
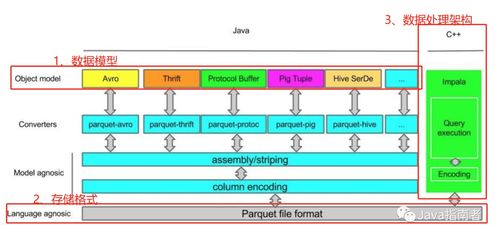
- 列式存储: 这是OLAP的标配。如Parquet、ORC等格式,因其高压缩比、可只读取查询所需列的特性,极大提升了扫描效率和I/O性能。选型时需考虑格式与计算引擎的优化集成度。
- 数据模型: 是采用经典的星型/雪花模型,还是宽表模型,亦或是支持预聚合的Cube模型。这需要与计算引擎的选择联动考虑。例如,ClickHouse更适合宽表模型,而Kylin则与Cube模型强绑定。
- 存储系统与架构:
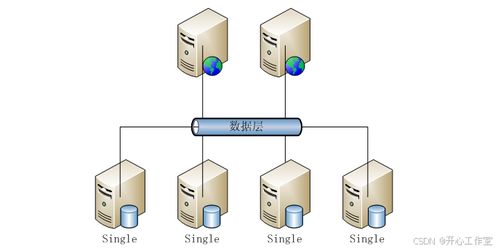
- 本地存储: 与计算节点紧耦合(如ClickHouse传统部署),延迟最低,但扩展性和可靠性需自行保障。
- 分布式文件系统/对象存储: 如HDFS、S3、OSS等,与计算分离,具有无限的扩展性和高可靠性,已成为云上主流选择。选型需关注存储与计算引擎间的网络性能和数据本地化优化策略。
- 索引结构: 高效的索引是快速查询的关键。需根据查询模式选择并配置合适的索引,如排序键(ClickHouse的主键)、位图索引、倒排索引、Min/Max索引等。
三、 核心选型决策框架
在实际选型中,必须将数据处理与存储服务作为整体权衡,关键决策因素包括:
- 数据规模与增长趋势: 数据量级(TB/PB级)和增量速度,决定了存储架构的扩展性需求。
- 查询性能要求: 对查询延迟(P99/P95响应时间)、吞吐量(QPS)的具体SLA。
- 查询模式分析: 是固定报表为主,还是灵活探索为主?查询的复杂度(多表Join、子查询、窗口函数)如何?
- 并发与用户规模: 同时在线查询用户数及查询队列管理需求。
- 成本考量: 包含硬件/云资源成本、运维复杂度和人力成本。开源方案可控但需自运维,云托管服务(如BigQuery、Snowflake)则简化运维但按量付费。
- 生态集成: 与现有数据栈(数据集成、BI工具、调度系统)的兼容性。
- 实时性需求: 是否需要支持从秒级到分钟级的实时数据更新与分析,这将导向ClickHouse、Doris、StarRocks等支持实时写入的引擎。
结论:OLAP技术选型的本质,是针对特定业务场景,在数据处理的计算范式、引擎能力与数据存储的组织格式、系统架构之间,寻找最优组合。没有“银弹”,只有最适合的平衡。通常建议通过概念验证(PoC),使用真实数据和典型查询负载对候选组合(如“StarRocks + 对象存储 + Parquet格式”)进行系统性测试,从而做出数据驱动的明智决策。
如若转载,请注明出处:http://www.starunicom.com/product/20.html
更新时间:2026-04-07 01:45:00