基于SpringBoot与Vue的Hadoop养老院数据分析与可视化系统 数据处理与存储服务设计与实现
随着人口老龄化趋势的加剧,养老服务的精细化、智能化管理变得日益重要。基于SpringBoot后端框架、Vue.js前端框架与Hadoop大数据处理平台的养老院数据分析与可视化系统,能够整合多源异构的养老院运营数据,通过高效的数据处理与存储服务,为管理决策提供直观、深入的洞察。本系统的核心在于其数据处理与存储服务层,它承担着原始数据的清洗、转换、存储与分析计算的重任。
一、系统架构与数据处理服务定位
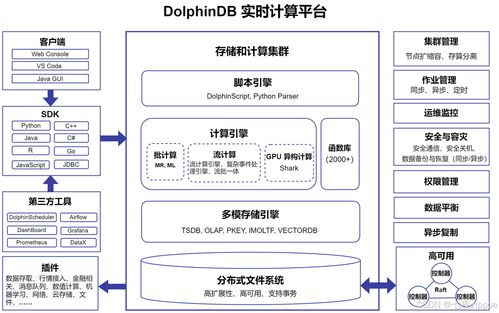
整个系统采用前后端分离的微服务架构。前端由Vue.js构建,提供友好的数据看板、图表可视化及交互界面;后端业务逻辑与RESTful API由SpringBoot微服务提供;而核心的数据处理与存储服务,则构建在Hadoop生态系统之上,作为一个相对独立但紧密集成的数据中台层。该服务层不直接处理前端请求,而是为上层的SpringBoot应用服务提供经过处理、聚合后的高质量数据,或接收其提交的原始数据入库与处理任务。
二、数据处理流程设计
数据处理服务遵循典型的ETL(抽取、转换、加载)流程,并针对养老院特定数据进行了定制化:
- 数据抽取(Extract):
- 数据源:数据来自多个渠道,包括养老院管理信息系统(如入住登记、健康档案、护理记录)、物联网设备(如智能床垫、穿戴设备传感器)、财务系统以及外部数据(如区域人口统计数据)。
- 抽取方式:对于结构化数据(如MySQL中的业务数据),使用Sqoop进行定期批量导入,或通过Canal监听数据库Binlog进行近实时同步。对于日志文件和传感器生成的半结构化/非结构化数据,则采用Flume进行实时采集,汇聚到数据管道中。
- 数据转换与清洗(Transform & Clean):
- 此阶段是提升数据质量的关键。利用Hadoop的MapReduce或更高效的Spark计算框架编写清洗逻辑。
- 具体任务包括:
- 格式标准化:统一日期、时间格式,规范字段命名。
- 缺失值处理:对长者健康监测数据中的缺失值,根据规则进行填充(如使用前后时间点的平均值)或标记。
- 异常值检测与修正:识别生理参数异常记录(如异常心率、血压),并结合护理记录进行验证或平滑处理。
- 数据集成与关联:将来自不同系统的数据通过长者ID、房间号等关键键进行连接,形成宽表。
- 敏感信息脱敏:对姓名、身份证号等个人信息进行脱敏处理,确保隐私安全。
- 数据加载与存储(Load & Store):
- 清洗转换后的数据被加载到Hadoop分布式文件系统(HDFS)中进行持久化存储,为海量数据提供廉价、可靠的存储基础。
- 为了支持高效的多维分析和快速查询,系统会将数据进一步建模后导入到Hive数据仓库中。Hive的表结构根据分析主题设计,例如:
dw<em>elder</em>basic(长者基本信息维度表)
dw<em>health</em>check_fact(健康检查事实表)
dw<em>service</em>consumption_fact(服务消费事实表)
dw<em>finance</em>fact(财务收支事实表)
- 对于需要实时查询或缓存的热点数据(如当日报警统计、在住长者概况),可以将Hive中聚合的结果或关键指标同步到HBase或Redis中,供SpringBoot后端快速调用。
三、数据存储架构
数据处理服务采用分层存储架构,以平衡存储成本、数据访问速度和分析需求:
- 原始数据层(Raw Zone):存储在HDFS上,保留从源头抽取的原始数据,格式不做改变,作为数据溯源和重新处理的依据。
- 清洗数据层(Cleansed Zone):同样位于HDFS,存放经过清洗、转换后的标准格式数据,是后续所有分析的数据基础。
- 数据仓库层(Data Warehouse Zone):基于Hive构建,按照星型或雪花型模型组织清洗后的数据,便于执行复杂的SQL查询和离线批处理分析,如月度健康趋势分析、年度费用报表生成。
- 数据服务层/数据集市(Data Mart/Service Zone):为满足具体可视化需求(如“失能长者护理强度分析”、“床位周转率仪表盘”),从数据仓库中进一步聚合、计算生成更细粒度的数据集,或存储在HBase/MySQL中供API快速访问。
四、服务集成与API设计
数据处理与存储服务通过封装良好的API与上层SpringBoot应用交互:
- 数据任务管理API:SpringBoot应用可以提交一个ETL作业请求(如“处理上月所有护理记录”),该服务接收后,调用YARN资源管理器调度MapReduce或Spark作业执行。
- 数据查询API:提供Restful接口,SpringBoot后端可以按需查询。例如,前端请求“近一周跌倒报警统计”,SpringBoot服务会调用本服务提供的相应API,该API可能触发一个预定义的Hive查询或从HBase中直接获取结果。
- 数据导出API:根据可视化需求,将分析结果(如预测模型输出、聚类分组)以JSON或CSV格式返回给前端。
五、技术栈
- 数据采集:Sqoop, Flume, Canal
- 分布式存储:HDFS
- 批量计算:MapReduce, Spark Core
- 数据仓库:Hive
- 资源调度:YARN
- 快速查询:HBase, Redis(缓存)
- 服务集成:SpringBoot(作为控制层和API网关,调用Hadoop生态组件)
###
在基于SpringBoot和Vue的养老院数据分析系统中,以Hadoop为核心的数据处理与存储服务扮演了“数据发动机”的角色。它通过可扩展的分布式架构,解决了养老院多源海量数据的存储、清洗与计算难题,将原始数据转化为有价值的信息资产。上层SpringBoot微服务与Vue前端则基于这些高质量的数据,构建出直观、动态的可视化界面,最终帮助养老院管理者实现从“经验驱动”到“数据驱动”的决策转变,提升运营效率与服务品质。该设计确保了系统的数据吞吐能力、分析深度以及前端的响应体验,为智慧养老提供了坚实的技术支撑。
如若转载,请注明出处:http://www.starunicom.com/product/15.html
更新时间:2026-03-30 15:18:36