基于大数据与机器学习的智能物流预测分析系统设计与实现
基于大数据与机器学习的智能物流预测分析系统设计与实现
一、项目概述
本项目是一个集物流数据采集、处理、存储、分析与可视化于一体的大数据智能系统,面向计算机专业毕业设计场景。系统以物流行业为背景,融合PyFlink、PySpark、Hadoop、Hive等大数据处理框架,结合深度学习与机器学习算法,实现对物流数据的深度挖掘与智能预测。
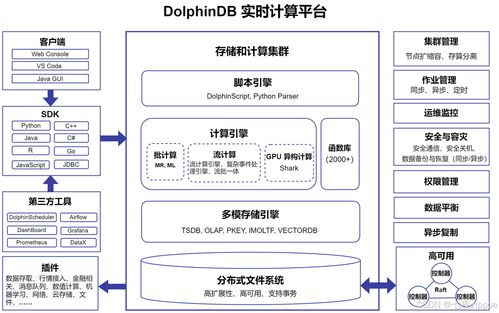
二、系统架构与技术栈
1. 数据采集层(物流爬虫)
- 功能:从公开物流平台、企业ERP系统、API接口等多元化来源实时/批量采集物流订单、运输轨迹、仓储状态等数据。
- 技术:Python爬虫框架(Scrapy/Requests)、数据清洗与预处理(Pandas)。
2. 数据处理与存储服务
- 批处理与存储:采用Hadoop HDFS作为分布式文件存储系统,使用Hive构建数据仓库,实现海量物流数据的结构化存储与离线分析。
- 实时处理:基于PyFlink构建实时数据流处理管道,对物流在途状态、实时位置等动态数据进行低延迟计算。
- 计算引擎:核心使用PySpark进行大规模数据的ETL(抽取、转换、加载)处理,并支持机器学习库(MLlib)进行模型训练。
3. 数据分析与智能预测
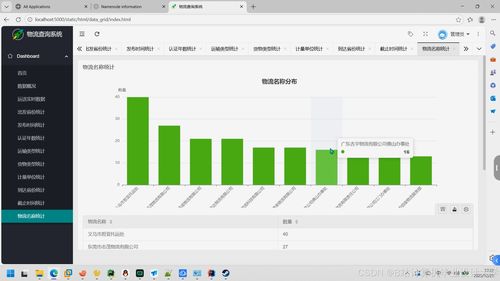
- 物流数据分析可视化:通过ECharts、Matplotlib等可视化库,将物流网络效率、配送时效、货物分布等关键指标以图表形式直观展示。
- 预测模型:
- 机器学习:利用Spark MLlib或Scikit-learn构建回归与分类模型,实现如“配送时间预测”、“货量预测”、“异常订单检测”等功能。
- 深度学习:可选方案包括使用TensorFlow或PyTorch构建LSTM神经网络,对复杂的物流时序数据(如未来一周的订单量趋势)进行更精准的预测。
4. 应用与展示层
- 提供Web管理界面(可基于Flask或Django开发),集成数据看板、预测结果查询、系统管理等功能。
- 生成自动化分析报告,支持结果导出。
三、毕业设计成果物
- 完整源码:包含爬虫脚本、Spark/Flink处理程序、机器学习模型代码、Web应用后端及前端代码。
- 详细设计文档:涵盖需求分析、系统设计、模块说明、部署指南等。
- 答辩PPT:系统介绍、技术亮点、实现过程、结果展示及展望。
- 讲解视频/演示:系统运行演示及核心代码讲解。
四、核心实现步骤
- 环境搭建:部署Hadoop集群(或使用单机伪分布式)、Spark、Flink、Hive,配置Python开发环境。
- 数据管道构建:
- 爬虫数据→Kafka(可选)→PyFlink实时处理→HDFS/HBase。
- 历史数据批量导入Hive。
- 特征工程与模型训练:在PySpark中提取物流特征(如距离、时段、货物类型等),划分训练集与测试集,训练预测模型并评估。
- 系统集成:将训练好的模型嵌入数据处理流程或提供API服务,在Web界面展示分析结果与预测值。
- 优化与测试:调整模型参数,优化系统性能,进行完整功能测试。
五、项目特色与创新点
- 技术整合性强:有机融合了大数据生态中的多项主流技术,体现完整的“数据采集→处理→分析→应用”链路。
- 业务结合紧密:聚焦物流行业真实痛点,提供可落地的预测与分析功能。
- 可扩展性高:模块化设计便于功能扩充,如增加路径优化、成本分析等模块。
六、
本项目通过构建一个完整的智能物流预测分析系统,不仅能够满足计算机专业毕业设计在复杂度、技术深度与实践性上的要求,同时也展示了大数据与人工智能技术在传统物流行业数字化转型中的巨大应用潜力。开发者可通过本项目深入理解从数据到决策的全流程,掌握企业级大数据系统的开发方法。
如若转载,请注明出处:http://www.starunicom.com/product/11.html
更新时间:2026-03-30 16:07:19